SORA+: building realistic VLM’s.

About:
This article is the first in the 2 article series to give a detailed description of the current open source models that can be referrenced in order to build an VLM pipeline that :
- Handles the current challenges faced by SORA(namely not generating more realistic videos and lack of prompt strategies vis a vis the other rules).
- And to build the more state of the art training network from scratch via using the pre-existing models freezed weight training using adapters.
Index:
- Introduction
- Explaining DiT model: the fundamental backbone.
- Current challenges and introducing V-JEPA and Imagebind models.
- Adapters: finetuning the pre-trained transformer LLM models.
- Proposing the model architecture on training on pre-existing models.
Introduction:
My interest in getting into writing this article is tweet Yann Le Cun on sharing the DiT model(using U-net or other autoregressive model variants) can be optimised and scaled to generate more coherent and realistic Videos from prompts.
This paper combined with the plethora of the papers that are published in the domain of high fidelity video generation using (Bytedance magicVideo , Alibaba’s EMO ) along with the advancements in the tooling automations (techniques on orchestrating the video generation tasks onacross various agents platforms using frameworks like ToolLLM) gives a good insight into how the video production tools that are being used in order to augment the workflows of the user.
SORA general architecture:
Currently based on the general description by OpenAI and diffusion transformers paper (DiT), these are group of architectures developed in variational0 autoencoder space, with the difference unlike using the UNet (previous benchmark model in CNN which has optimised architecture) it integrates transformer.

here the DiT consist of the following components :
- Foundational transformers: Transformers have been extensively being trained in predicting in generating the non spatial data (like CLIP embeddings that forms the core component of the architecture).
- Deionising diffusion probablistic model : these are the time dependent version of the diffusion models (i.e they try to predict the noise based on the nature of the photo to be predicted) and use efficient sampling techniques vis traditional ones.
And the forward pass of the DiT works as follows (credits to tom Yeh and reference implementation of meta):
- User provides the Prompt with the diffusion step parameter (which corresponds to the level of noise that is attenuated with the given video ) along with the given image / video as the benchmark. Consider the prompt being “Birds passing through narrow alleyway through the bridge” with the t = 3.
- Then the corresponding video is converted into matrix of 4 dimensions (representing the eucledian coordinates and the time parameter that is sampled with the attenuation parameter taken from the user).
- These 4 parameters (x,y,z,t) are initialized with the embedders,which are:
— PatchEmbeddings of given photo using timm library, following the design of the conv2d.
— TimestepEmbedding: this is the sequential combination of the linear layer along with Sinusoidal activation layer for the DDPM model to work.
- Then the noise is added to the ideal image (similar to the pruning techniques in the language transformer model ).
- Its then passed through repeatitive transformer blocks which are 3D blocks consisting of the attention layer along with the activation layer.
— Shifting layer: This layer adjusts the amount of noice that is to be added to the varius sections of the given image speciment associated to the prompt. this is implemented by using the adaLN-Zero modulation technique , which is further divided into the 5 steps (with example) :
** Preprocessing : here the each img to be generated, it checks the features of the prime subjects (in our case the bird and the various objects and lighting in the alleyway) and highlights them.
** Conditioning: this then tries to retrieve more details (the orientation, other spatial properties) of the given objects during the period of time in order to then do then adjust the noise levels
** Modulation: This transformation of noise tries to adjust based on the visual and texture properties of the video throughtout the transition of the application.
**Attention layer: based on the modulation layer adjusting the different readings of the predicted pixels, the attention layer (of type multi head) then considers the various sections that are to be then generated further to enhance the result of the given video sequence based on the prompt.
- * MLP transition: The last step generates the remaining frames of the video based on the probablity density of the noise (from Gaussian/ time dependent modulations) using the decoder to generate the video from the given prompt.

Addressing challenges and potential evolution of infrastructure:
Given the immense progress in the quality of generating realistic model parameters has been great but it still needs more working in following aspects:
- In terms of generating the actual reality of the universe (human motions, the 5 senses and their interaction with surfaces and physics etc). And given that even if the SORA model in the coming days is gonna be more proactively encoding the physics engine rules (as many contemplated an addressed by NVIDIA research scientists), for me the fact that “only textual prompt for model in order to generate the videos at a level consumable for the multimedia campaign ads and other realistic adds is gonna be a major challenge”.
- Also even if the video models do a better job in terms of providing better rendering in terms of consistent physical properties , it pales in terms of the contextual attention while generating the tokens and general sense in predicting a storyline of the given theme based on the given input prompt.
All of these shortcomings require the need to develop an evolutionary framework combining the the benefits of
- Encoding the context as well as associated multimodal details in the prediction layer (as from the Meta’s ImageBind that tried to generate the corresponding IMU voice and audio metadata).
- Along with building the model unsupervised and trained from sparsed trained data , creating joint embeddings from across the various parameters (V-JEPA).
- And finally conceptualizig how to develop the SaaS platform that consist of UI components that takes multiple format of prompts in order to generate more robust workflow vis traditional chat interfaces.
Introducing JEPA w/ ImageBind for realistic media generation:
JEPA architecture was the brainchild of Yann-le-Cunn vison to build autonomous machine intelligence (not to be misunderstood with AGI ;)) to build self supervised models for training to prediction / classification tasks in the multimodal domains to orchestrate intelligent behaviour like learning the underlying characterstics of image, planning and the ability to connect these modalities to predict the results more grounded with the reality.
Its architecture consist of following characterstics:
1. Joint-encoding embedings : This forms the building blocks for the backbone network of self supervised learning to encode the various incomplete representations of the same category of image frames to generate the embeddings that represent the visual representation combined by the other chracterstics in enviornment by using autoencoder.
2. Predictor model: It predicts the representation of the predicted video for training from the reference training video
Combination of both Feature Prediction and pixel prediction approach, in order to get the best of both approaches (having the details of the given prediction of the prompt video result with the corresponding charactertics of the user).
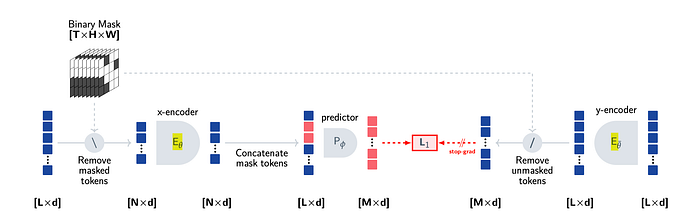
And the encoder here is entrained with the condition that the predictions computed from the one aspect of the training video should be predicted from the corresponding representations from the other part of the given video and the overall optimization method comes out to be:
minimizeθ,φ ∥Pφ(Eθ(x),∆y)−sg(Eθ(y))∥1
Which means the model tries to minimize the L1 distance b/w the Reconstructed image (aka Pφ(Eθ(x),∆y) using the encoding of training image and affinity of reconstructed image subtracted by the transformed encoding of the transformed image). thus it tries to generate the final image (y) by encoding the noise on the initial image at the same time keeping the elements random by doing masking.The encoder / decoder architecture is represented by the ViT architecture where the patch to be masked is defined in the 3D (with the 2d section represnted by the 16*16 blocks with the N temporal time results).
In general the the parameters that are to be considered for finding the learning rep from video are defined by following parameters:
- How the objectives of pixel prediction vs feature prediction are being managed.
- how the variety of attention mechanisms on training of the variety of unsupervised video training dataset ( Average pooling v/ adaptive pooling) in order to improve the prediction score for the datasets
ImageBind: the glue for multimodal analysis
- its a multimodal embedding generational model trained using contrastive learning of pairs of examples across the different visual / modal sensor domains along with the corresponding prompt in order to generate the resulting output in different domains which are adapted in the terms of enviornment rules
- It consist of generaitng the embeddings of the given image Ii and the embeddings of the other sensor parameters (Mi) in order to then train and optimize on the following log formula (called as infoNCE loss)
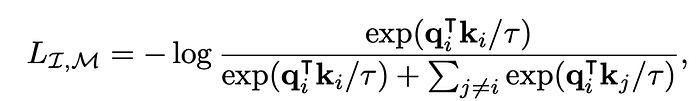
3. And then it does the emergent zero shot classification as it traines the text prompt with the embedding space generated with the multiple prompts consisting of various sensory(IMU ) data.
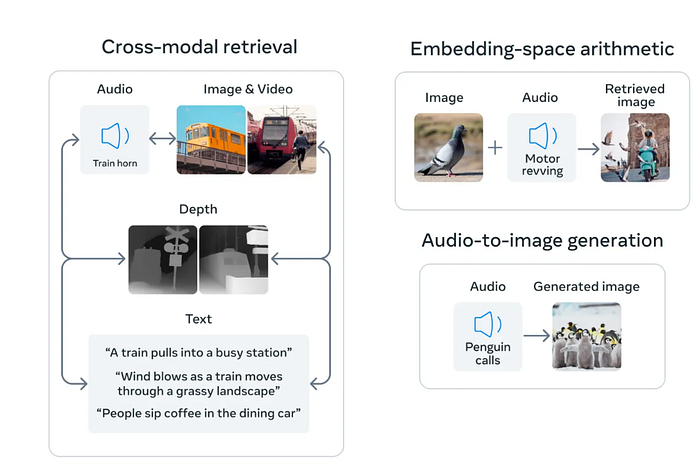
This model will be an major help for for encoding the various modalities in the embedding which will be referenced by the 3D physics graph neural network by deepmind (explained in later sections).
Adapters: getting up to speed with finetuning pretrained llm models.
Now given that most of the above models are trained already on large corpus of video and other modalities of data and are available in opensource / optimised format (like GGUF on higgingface hub), thus trying to finetune those models based on our specific generation task can be done thanks to the frameworks called as adapters .
These are wrapper implementations integrated between the well known patterns of the components of transformer models (encoder/decoders, attention layer, activations) that are trained, by applying non linear fully connected layers that are trained on the specific tasks , while keeping the overall parameters and the training function and inference of the overall model intact.
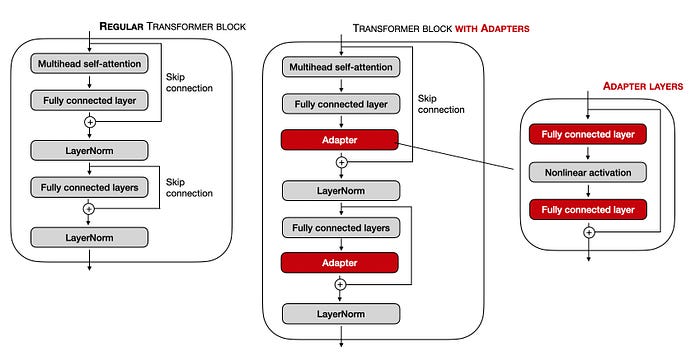
These were developped initially by the huggingface adapters library (now renamed as the adapterhub) which consist of the pre-defined implementation of the various well known models .
other framework that i will reference here are:
- The refiners adapter library (as they had implementation of most of the current benchmark VLM model architecture which were not implemented by the adapterhub)
- Tenecent T2I adapter that combines the corresponding image prompts along with the corresponding text description which is idle for training the pre-existing training models as ours.
Thus adapters will be the important component for building our overall finetuned model architecture without developing the neural model from scratch.
Devising the architecture by combining the above models:
Now we need to conceptualise how to combine the unsupervised joint embedding training across the various modalities within the video in order to scale the creation of realistic videos from prompts.
We will be taking the relevant literature and open source version as base benchmark(open sora hosted on the hub ) which is implementation of DiT as the core architecture
Task description:
We consider that the model consist of the trained on the videos with the text description of the relevant actions happening in the given video. User will provide the prompt description (regarding the nature of video to be created and focusing on the certain aspects of the video), and then output video is the generated video which includes the simulation that respects the rules of the physical simulations (rigid bodies , having natural motions of the humans and natural animate bodies).

The pipeline is divided the whole model pipeline into 4 stages:
- Video training of the model:
- First we will be passing the video frame sequences to the encoder, by passing the consecutive frames of the video which are then passed to the ViT encoder, in order to extract the features. the architecture will be developed as follows:
— Encoder : Using the adapterhub supported model for the integration of the pre-trained video encoding model.
- After the video is divided into n*m patches and then we will integrate the adapters to passed through the pre-trained encoder (one of the well knowbn architecture is ViT Masked Autoencoder ) .
For the text encoder , we reference from the adapterhub huggingface based uploaded model registry (listed here) which are trained with the different tasks in NLP. for our usecase we can take either of the following category tasks based on the performance:
- Name entity recognition task (in order to get pretrained model to adapt to detect defined places, subjects and actions in the prompt )
- Multilingual knowledge integration: In order to get the relation topic relation across various concepts using the concept of graph neural networks
2. Audio pipeline (optional): This pipeline is to generating the approximative audio voice corresponding to the text prompt description for generating the video. there can be various potential pipelines we can use:
- Using NVIDIA NeMO benchmarked speech synthesis TTS pipeline that consist of generaitng the Mel representation from the text query and then converting to the audio voice. this is more in-depth model that
- And if your videos have to specifically cater to the generation of the human voice , benchmark models like the Coqui-TTS, open-whisper and others can be finetuned based on your needs.
Some of the challenges (and potential solutions )in the above TTS approach that i will describe in the upcoming article is:
- The lack of context detailing the audio sounds of the various objects and the actions in the potential video generation (like in case of the screeching sound and electric spark in case of the train ) will need to be defined explicitly in the prompt context.
- Getting the multimodal dataset with the necessary datasets in order to train the audio text pair to the encoder (or to finetune from the previous existing model) is challenge for the realistic model.
3.Joint embeddings : And once the both encoders are trained, now comes the step to create the joint embeddings (k,v) based on the given query q (which will be the text encodings of the given query on which you want to run attention mechanism to the given result).
Following is the peudoalgorithm implementation of how we will implement the above 3 stages.
from adapters import ViTAdapterModel, AutoAdapterModel, training
from transformers import T5ForConditionalGeneration
from huggingface import hf_downloader_function
import cv2 import VideoCapture
from torch.nn import MultiheadAttention
def audio_encoding():
##TODO
def video_encoding(video_path, result_img_path_dir, encoding_dim=(n,m), sampling_size):
## transformation for developing the video to return the specific encoding to the results.
video_frames_fetch = VideoCapture(video_path)
height_frame = int(video_frames_fetch.get(cv2.CAP_PROP_FRAME_WIDTH))
width_frame = int(video_frames_fetch.get(cv2.CAP_PROP_FRAME_HEIGHT))
frames = []
## first getting the frames from the initial version of the video
while True:
ret, frame = cap.read()
if not ret:
print("No more frames available.")
break
if frame_count % sampling_size == 0:
frames.append(frame)
frame_count += 1
cap.release()
cv2.destroyAllWindows()
processing_frames = []
# conversion to the frame tensor frames with time
## reference: https://pytorch.org/vision/stable/transforms.html
for frame in frames:
frame_tensor = torch.from_numpy(frame).float()
# Resize the frame using torchvision transforms
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(encoding_dim),
transforms.ToTensor(),
transforms.Normalize(mean=[], std=[]), # Normalize (optional)
])
resized_frame = transform(frame_tensor)
preprocessed_frames.append(resized_frame)
## TODO: in case you want to train on the decoder from scratch, check the
## ref implemebtation: https://github.com/lucidrains/vit-pytorch/blob/main/examples/cats_and_dogs.ipynb
## else i am gonna use the pre-defined adapter for the specific task trained encoder model.
text_encoder = AutoAdapterModel.from_pretrained("google/t5-small")
video_encoder =video_encoding(.....)
audio_encoder = audio_encoder(...)
## TODO: need to determine the dimensions opf the architecture for the encoding / masking
## and also the key and value transformation for the queries
multihead_attention = MultiheadAttention(....)4. Physics regularization model:
Now in order for the decoder to generate the model that appears realistic (i.e has the more realistic physics model description in the 3D aspects) , there has been many approaches in the SOTA research that are being implemented in this regard :
- rombatt and blattman etal tries to define how the current stable diffusion models are facing the challenges in also generating the realistic scene of the subjects in the video and how to come up with the alternative augmentations in the autoregressive models in order to get the benefits of the near real time generation but more realisitc results.
- Paper from the google mind that defines more active approach of “developing the neural rendering function in order to learn the particle / object dynamics after being trained only from RGB videos.
- And the Open-SORA approach of using DPM solvers from hf’s diffusers library , which develops the higher order differential equation in the diffusion model in order to generate the realistic scene generation taking into consideration the consistency of the objects and the nearby frame.
My approach will be to develop on the best characterstics of all of these appraoches and thus for the initial version i came up with the following approach :
- Getting the result from the generated images from the video pipeline and then implementing the object detection pipeline in order to define the various sections of the image that requires the realistic augmentation.
- Then passing the parameters to the graph convolutional network that is trained on the particle simulation or the domain knowledge of the various modal data (and will be explained in next series of article) which will be then converted to embeddings in order to generate more precise results on the rendering function on the simulators like the Mujoco / blender etc .
TLDR;
And thats it for the initial description of the augmented SORA model that generates the realistic video generation by taking the concepts from the various state of the art video , audio and multimodal generation of the articles .
This article gives the template to the AI devs in the field how to think across the domain in order to build SOTA models by agglutinating various techniques and understanding the design thinking of the various constraints that come while building the content generation pipeline in the field of generative AI.
In order to build this pipeline into production and resolving the challenges of QA, llmops and performance is something a big endaevour and i will do indeed put time to explain it in the next series of article .
Till then thanks for reading the article , i will appreciate your feedbacks and criticism regarding the article and please follow the medium blog along with my github and huginggface handle to get the source code of the implementation.